A few things you need to know about Megatron-LM DistributedOptimizer
The Megatron-LM distributed optimizer is a code with a complex interface but good performance. There are some stories hidden under the complex interface, as well as the elegant theoretical design of ZeRO-1. This note is to record the stories behind these complex interfaces.
I. Dauntingly complex interface
DistributedOptimizer has a dauntingly complex interface. I have organized them as follows
Basic optimizer functions:
- get_parameters
- zero_grad
- state_dict
- load_state_dict
- step
TP/SP+PP:
- get_main_grads_for_grad_norm
- get_model_parallel_group
- allreduce_word_embedding_grads
- allreduce_position_embedding_grads
- allreduce_embedding_grads
- allreduce_layernorm_grads
- allreduce_router_grads
ZeRO:
- build_model_gbuf_param_range_map
- build_model_gbuf_range
- build_model_gbuf_range_map
- build_model_param_gbuf_map
- build_optimizer_group_ranges
- build_model_and_main_param_groups
- get_model_param_range_map
- save_parameter_state
- load_parameter_state
- get_model_buffer_dp_views
- get_model_grad_buffer_dp_views
- get_model_param_buffer_dp_views
- reduce_model_grads
- gather_model_params
Mixprecision:
- clip_grad_norm
- get_loss_scale
- scale_loss
- reload_model_params
helpers:
- count_zeros
II. How is ZeRO-1 implemented?
ZeRO-1 is main function of DistributedOptimizer. Before starting the introduction, it is highly recommended to read the documentation written by Megatron-LM to DistributedOptimizer first. It’s silky smooth and clear.
For ZeRO-1, optimizer state memory space and calculation must be distributed across data parallel ranks. DistributedOptimizer does it in optimizer.step, and in detail, by reduce-scatter gradients, then update optimizer state and parameters, and finally all-gather updated parameters. This sequence of operations can be visualized in the following data flow figure.
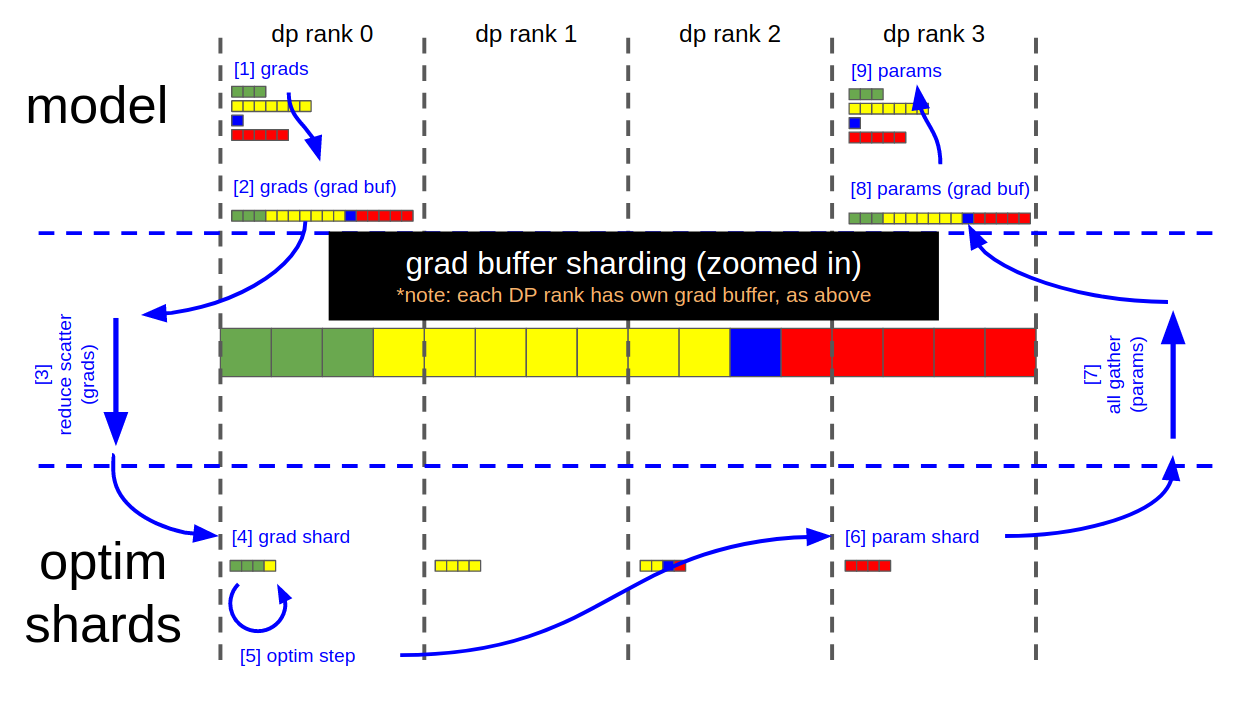
As can be seen, a key design is that gradients and parameters share the same memory space, and they are evenly divided among DP ranks. This memory space called gbuf in the code, and many functions here resolve around gbuf operations.
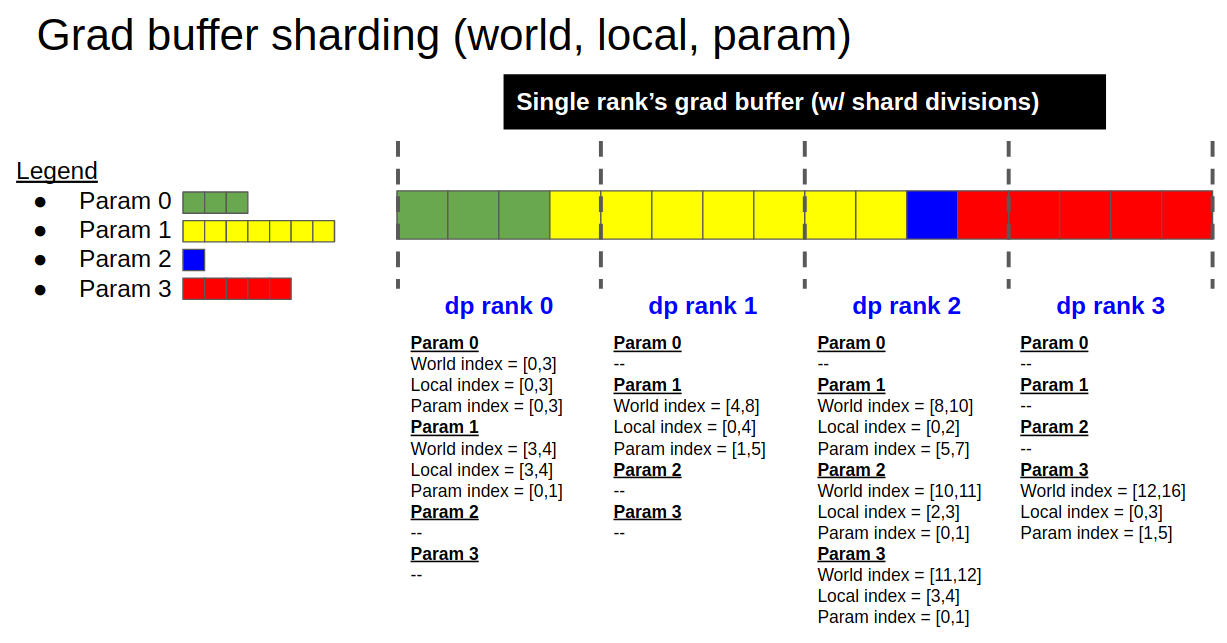
In the function build_model_gbuf_param_range_map, the global and local indexes of all parameters/gradients are constructed. These indexes build on gbuf, used to divide gradients, parameters, and parameter groups. There are three additional gbuf functions that provide interface functions around this core function. These are build_model_gbuf_range, build_model_gbuf_range_map, and build_model_param_gbuf_map.
The function build_model_and_main_param_groups completes the operations of partitioning parameters and parameter groupss, which are divided according to the previously calculated index. This function also includes an operation that creates an fp32 copy for the fp16/bf16 parameters.
The functions reduce_model_grads and gather_model_params execute reduce-scatter and all-gather operations respectively.
Here is a brief description of other functions:
-
build_optimizer_group_ranges- This function builds a mapping of model parameter and group index for all parameters. -
get_model_param_range_map- Given a model parameter, this function retrieves the index sub-range of the parameter that the data-parallel rank owns. -
save_parameter_state- This function copies parameters and optimizer shards, gathers them on DP rank 0, and saves them to disk. -
load_parameter_state- This function performs the reverse operation of save_parameter_state. -
get_model_buffer_dp_views- This function is agbufreader that indexes separately by model id and data type. -
get_model_grad_buffer_dp_views- This function is an application ofget_model_buffer_dp_viewsand is used to read the gradient buffer. -
get_model_param_buffer_dp_views- This function is another application ofget_model_buffer_dp_viewsand is used to read the parameter buffer.